เส้นทางอัปสกิลจาก Data Analyst สู่สาย Data Science & ML เติมทักษะอะไรบ้างให้ตอบโจทย์ตลาด
จาก Data Analyst สู่ Data Science & ML ต้องเติมสกิลอะไรบ้างถ้าอยากอัปเงินเดือน
การขยับขยายสายงานจากนักวิเคราะห์ข้อมูลไปสู่สายงาน Data Science & ML เป็นหนึ่งในเส้นทางที่ช่วยสร้างมูลค่าเพิ่มและยกระดับฐานเงินเดือนให้สูงขึ้นอย่างก้าวกระโดด โดยผู้เขียนจำเป็นต้องเปลี่ยนผ่านทักษะจากการมองย้อนอดีตเพื่อหาคำตอบ (Descriptive Analytics) ไปสู่การพยากรณ์อนาคตด้วยอัลกอริทึมขั้นสูง (Predictive Analytics)
การเติบโตในสายอาชีพนี้ไม่ใช่เรื่องที่เป็นไปไม่ได้สำหรับคนที่มีพื้นฐานการทำ Data Analytics อยู่แล้ว เนื่องจากคุณมีแต้มต่อในเรื่องของ Business Domain Knowledge หรือความเข้าใจในธุรกิจและการมองภาพรวมของข้อมูลอย่างทะลุปรุโปร่ง สิ่งที่คุณต้องเติมเต็มคือวิทยาการคอมพิวเตอร์ ตรรกะทางคณิตศาสตร์ และการเขียนโค้ดที่ยืดหยุ่น เพื่อสร้างเครื่องมือที่จะทำงานร่วมกับระบบ AI Analysis ในการขับเคลื่อนองค์กรยุคใหม่
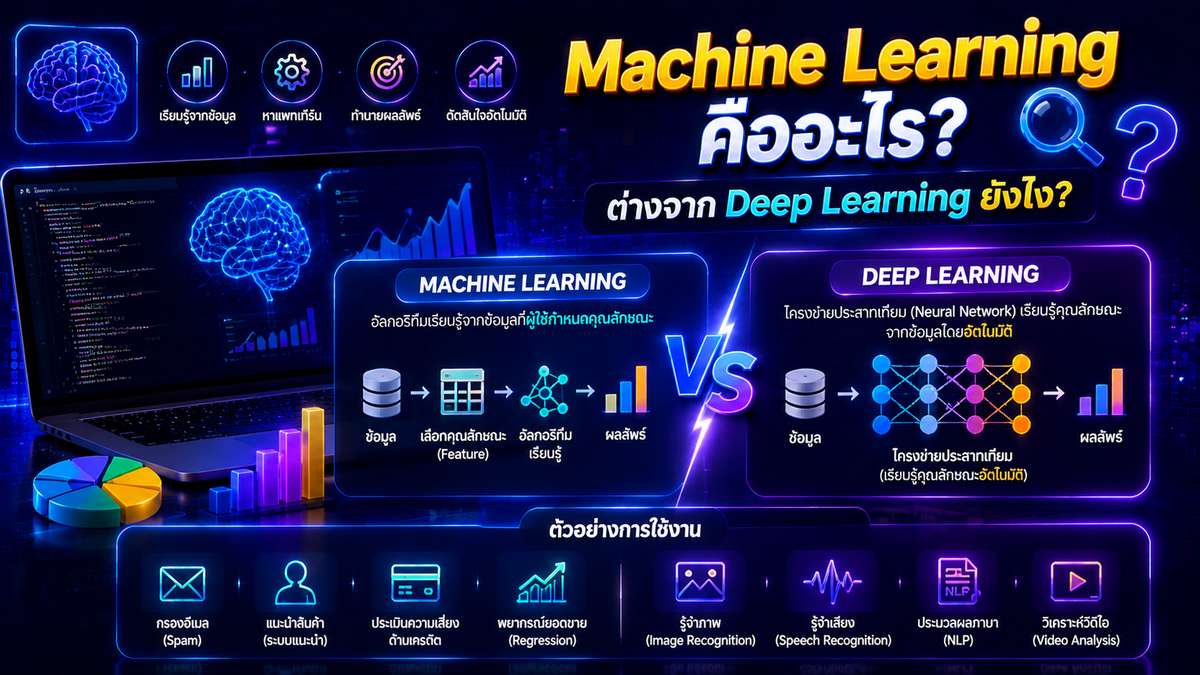
ทำความเข้าใจความต่างและนิยามว่า Data Science & ML คืออะไร
Data Science & ML คือการผสานวิทยาศาสตร์ข้อมูลเข้ากับระบบการเรียนรู้ของเครื่องเพื่อสร้างโมเดลอัจฉริยะที่สามารถทำนายผลลัพธ์ล่วงหน้าได้อย่างแม่นยำจากฐานข้อมูลขนาดใหญ่
การจะก้าวข้ามผ่านข้อจำกัดเดิมๆ นักวิเคราะห์จำเป็นต้องเข้าใจภาพรวมก่อนว่า data science คือ กระบวนการค้นหาความรู้และข้อมูลเชิงลึกจาก Data ที่มีความซับซ้อนผ่านกระบวนการทางวิทยาศาสตร์ ส่วนเรื่องที่ว่า machine learning คือ อะไรนั้น มันคือสับเซตหลักที่อยู่ภายใต้เทคโนโลยีนี้ ซึ่งเน้นไปที่การสร้างระบบหรืออัลกอริทึมให้สามารถเรียนรู้และพัฒนาความแม่นยำได้ด้วยตัวเองจากประสบการณ์หรือข้อมูลที่ป้อนเข้าไป โดยไม่ต้องอาศัยการเขียนโค้ดคำสั่งแบบตายตัวทุกครั้ง
ติดปีกการเขียนโค้ดและการจัดการข้อมูลระดับ Advance
การเขียนโปรแกรมด้วยภาษา Python และการจัดการข้อมูลด้วยไลบรารีประสิทธิภาพสูงคือหัวใจสำคัญที่เปลี่ยนวิธีทำงานจากการกดใช้เครื่องมือสำเร็จรูปไปเป็นการควบคุมโครงสร้างข้อมูลได้อย่างอิสระ
ในการเริ่มต้นเขียนโค้ดเพื่อจัดการ Big Data สิ่งแรกที่คุณต้องทำความเข้าใจคือ pandas คืออะไร ซึ่งอธิบายได้อย่างง่ายว่ามันคือไลบรารีทรงพลังบน Python ที่เปรียบเสมือนสเปรดชีตเวอร์ชันนักพัฒนา ช่วยให้นักวิเคราะห์สามารถทำความสะอาดข้อมูล (Data Cleaning) จัดการตาราง และแปลงรูปแบบข้อมูลปริมาณมหาศาลได้อย่างรวดเร็วกว่าการใช้ซอฟต์แวร์ทั่วไปหลายเท่าตัว
เปรียบเทียบความแตกต่างด้านขอบเขตการทำงาน
เทคนิคการสร้างและประเมินโมเดลเพื่อความแม่นยำสูงสุด
การพัฒนาโมเดลปัญญาประเมินผลที่มีประสิทธิภาพสูงจำเป็นต้องพึ่งพากระบวนการทดสอบที่รัดกุมเพื่อป้องกันไม่ให้เกิดความคลาดเคลื่อนเมื่อนำไปใช้งานจริงในสถานการณ์จริง
ขั้นตอนที่ห้ามมองข้ามเด็ดขาดในการทำเทรนนิ่งโมเดลคือการทำ cross validation ซึ่งเป็นเทคนิคการแบ่งชุดข้อมูลออกเป็นส่วนย่อยๆ เพื่อสลับกันนำมาใช้เทรนและทดสอบประสิทธิภาพ วิธีนี้ช่วยการันตีได้ว่าโมเดลที่เราสร้างขึ้นมานั้นมีความเสถียร ไม่เกิดปัญหา Overfitting (ฉลาดเฉพาะในห้องทดลองแต่ใช้งานจริงไม่ได้) ทำให้นักวิเคราะห์มั่นใจได้ว่าระบบทำนายผลลัพธ์จะมี Accuracy AI ที่น่าเชื่อถือสูงสุดตามมาตรฐานสากลก่อนส่งต่อไปแสดงผลบนแดชบอร์ด Data Viz ของผู้บริหาร
คำถามที่พบบ่อยเกี่ยวกับสายงานใหม่
คำถาม หากต้องการทำข้อสอบสัมภาษณ์งานตำแหน่ง Data Scientist เรื่องไหนที่มักจะถูกหยิบยกมาถามบ่อยที่สุด
คำตอบ นอกจากคำถามเรื่องการเลือกใช้อัลกอริทึมให้เหมาะกับโจทย์ธุรกิจแล้ว เรื่องของการทำ Feature Engineering และอธิบายความแตกต่างของ Metric ในการวัดผล เช่น Precision, Recall และ F1-Score ถือเป็นจุดตายที่ผู้สัมภาษณ์ใช้คัดเลือกคนทำงานจริงออกจากคนที่จำทฤษฎีมาตอบ
คำถาม ตลาดแรงงานในปัจจุบันยังคงต้องการตำแหน่งนี้สูงอยู่ไหม และจะโดน Generative AI แย่งงานหรือไม่
คำตอบ ตลาดยังคงมีความต้องการสูงมากอย่างต่อเนื่อง เพราะ Generative AI ทำหน้าที่เป็นเพียงผู้ช่วยในการเขียนโค้ดเบื้องต้น แต่กระบวนการออกแบบสถาปัตยกรรมข้อมูล ตรรกะทางคณิตศาสตร์เบื้องหลังโมเดล และการปรับแต่งพารามิเตอร์ให้เข้ากับบริบทเฉพาะของแต่ละองค์กร ยังคงต้องพึ่งพาผู้เชี่ยวชาญที่มีทักษะระดับสูงในการตัดสินใจ
คำแนะนำเพื่อการเติบโต: สำหรับนักวิเคราะห์ข้อมูลที่พยายามเปลี่ยนสายงาน การทำโปรเจกต์ส่วนตัว (Portfolio) ที่นำข้อมูลสาธารณะมาทำความสะอาด สร้างโมเดลทำนายผลลัพธ์ และประเมินผลอย่างละเอียดผ่าน GitHub จะเป็นหลักฐานเชิงประจักษ์ที่แสดงถึงประสบการณ์และความเชี่ยวชาญได้ดีกว่าการระบุเพียงชื่อใบเซอร์ในเรซูเม่ของคุณ